Tutorial
This tutorial will walk you through the process of using loanpy to discover old loanwords.
Here is an illustration of the loanword detection framework with a minimal example:
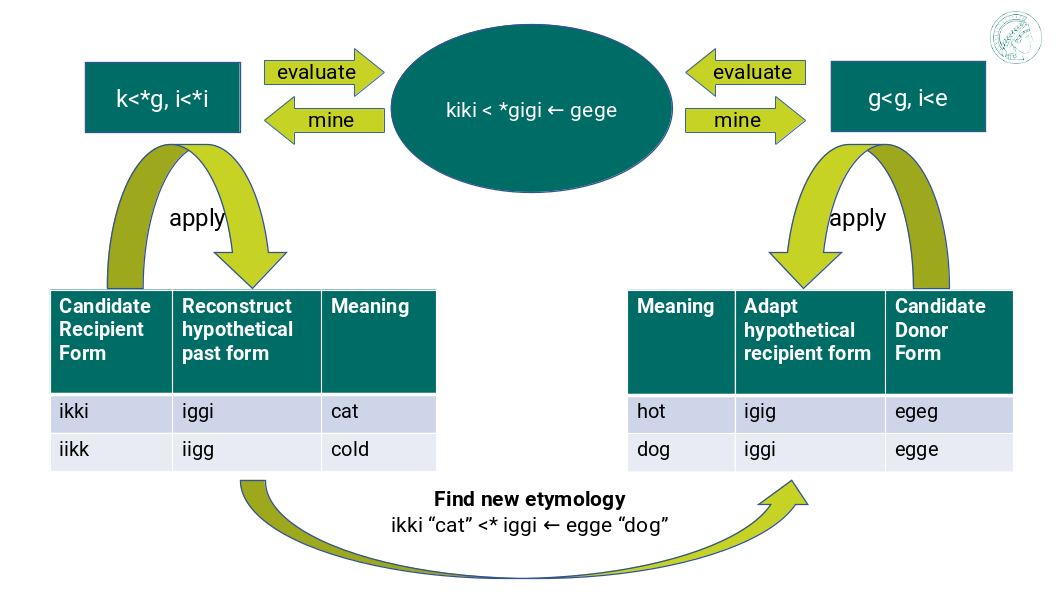
Mine sound correspondences from an etymological dictionary, evaluate their predictive power, input them to a sound change applier to generate pseudo-adapted and pseudo-proto-forms, and search for phonetic and semantic matches between those predictions.
Step 1: Mine sound correspondences
Grab an etymological dictionary and mine information of how sounds and phonotactic patterns changed during horizontal and vertical transfers.
In the minimal example, our dictionary contains only one etymology, namely a horizontal transfer “gigi ← gege” and a vertical one “kiki < gigi”. If we mine the sound correspondences we get the rule “g from g, i from e” in horizontal transfers and “k from g, i from i” in vertical ones. In terms of phonotactics, we can mine “CVCV from CVCV” both horizontally and vertically.
This is achieved with loanpy.scminer.get_correspondences
For an implementation with a detailed guide visit Part 3 (steps 1-4) of ronataswestoldturkic’s documentation.
Step 2: Evaluate the predictive model
How good are the predictions made from the mined sound correspondences?
Our minimal example is a perfect model that predicts with 100% certainty that <kiki> goes back to <gigi> and that the donor form of <gigi> is <gege>.
This is achieved with loanpy.eval_sca.eval_one
For an implementation with a detailed guide employing concepts from statistics such as leave-one out cross-validation (LOOCV), the receiver operating characteristics (ROC) -curve, and the area under the curve (AUC), visit steps 5-6 in part 3 of ronataswestoldturkic’s documentation
Step 3: Apply sound correspondences
Take the information mined from the etymological dictionary and apply it to unseen words. Create hypothetical proto- and adapted forms by simulating their horizontal and vertical changes.
In the minimal example this means predicting that <ikki> must go back to <iggi> and <iikk> to <iigg>, based on the mined sound correspondences for vertical transfers. Likewise, <egeg> must turn into <igig> and <egge> into <iggi> during horizontal transfers, based on the extracted sound correspondences.
This is achieved with the loanpy.scapplier module
For an implementation with a detailed guide to predict vertical transfers visit gerstnerhungarian’s documentation and for predicting horizontal transfers (loanwords) visit koeblergothic’s documentation.
Step 4: Find old loanwords
Search for phonetic matches between predicted loanword adaptations and predicted proto-forms. Calculate the semantic similarity of the meanings associated with each form in a match. List the phonetic matches with the highest semantic similarity.
In our minimal example this means to first go through the cartesian product of phonetic matches. If our criterion for a match is phonetic identity, we get:
iggi - igig: no match
iigg - igig: no match
iggi - iggi: MATCH
iigg - iggi: no match
Now we can register that <iggi> is our only match. The meanings associated with it are “cat” and “dog”. If we assess these two meanings as sufficiently similar, then we can propose a new etymology: <ikki> “cat” goes back to a proto-form <iggi>, which was borrowed from <egge> “dog”.
This is achieved with the loanpy.loanfinder module
For an implementation with a detailed guide visit GothicHungarian’s documentation.
Conclusion
Congratulations, you’ve completed this tutorial on loanpy! You should now have a good understanding of how to use loanpy to find old loanwords.
If you have any questions or feedback, please don’t hesitate to reach out to me, e.g. via e-mail or Twitter.
Further Reading
LoanPy was part of my dissertation-project. A link to the monograph will be made public as soon as available, probably around September 2023. Stay tuned.